The Wordle craze has inspired many clones, including Worldle. In this version, you are shown an outline of a country or territory (including uninhabited islands) and have six guesses to figure out which country or territory is displayed. With each incorrect guess you are told how far the center of the country you guessed is from the center of the correct country in kilometers, as well as the general direction.
When playing the other day, I had this outline and did not even have a clue about what country it could be.
Outline of the selected country.
So I started with some random guesses, hoping I could narrow it down by rudimentary triangulation. After three guesses I had the following results.
The best I could tell was that the correct answer was somewhere in the middle of the South Atlantic Ocean but it was probably a small island that would be hard to find by panning through Google Maps. So I decided to use R and the {sf} package to help locate the correct answer.
The goal with the code is to find the centers of each guess, draw circles around those centers, each with a radius as given by the distance in the game, then see where the three circles intersect. This is the general idea behind triangulation and should show us roughly where the correct country is positioned.
First, I needed to find the centers of my incorrect guesses, so I used the {rnaturalearth} package to pull up the boundaries of the countries guessed so far and then use st_centroid() to compute their centroids.
library(sf)
library(dplyr)
data(countries110, package='rnaturalearth')
# this is an sp object so we make it into sf
countries <- countries110 |> st_as_sf()
# here we narrow it down to the countries we want to keep
starting <- countries |>
select(brk_name) |>
inner_join(guesses, by=c('brk_name'='Country')) |>
# leaflet makes you assign your own colors
mutate(color=RColorBrewer::brewer.pal(n(), 'Set1'))
# this finds the centroids of each country
# the warning doesn't apply to us
centers <- starting |>
st_make_valid() |>
st_centroid()
## Warning in st_centroid.sf(st_make_valid(starting)): st_centroid assumes
## attributes are constant over geometries of x
# these are the centers of each guess
centers
brk_name
Distance
Direction
geometry
color
Iceland
13427
South
POINT (-18.76554 65.07986)
#E41A1C
Lesotho
3404
Southwest
POINT (28.17182 -29.62479)
#377EB8
Sierra Leone
7144
South
POINT (-11.79541 8.529459)
#4DAF4A
Now we map these points to see how we’re doing. For this blog, the maps are static though when recreating this in the console or an HTML rmarkdown document, they would be pannable and zoomable.
library(leaflet)
leaflet() |>
addTiles() |>
# we use the color column defined earlier
addPolygons(data=starting, fillColor=~color, stroke=FALSE, opacity=1) |>
addMarkers(data=centers)
The countries we guessed so far and the center of their polygons.
For each of our guesses, we want to draw a circle extending out from their centers. The radius of each circle is given by the distance reported in the game. To compute these circles we use st_buffer() which creates a polygon around a given geometry, the points in this case.
The latest version of {sf} uses spherical geometry by default. This means we can pass an sf object that uses lat/long to st_buffer(), specifying the dist argument in kilometers, and st_buffer() will account for the curvature of the Earth. In previous versions, we would first convert to a meters-based projection (which is hard to do on a global scale) then compute the buffer then convert back to lat/long. Spherical geometry is a huge improvement.
st_buffer() returns the entire circle as a filled in polygon, but we actually just want the boundaries of the circles because we want to compute the intersection of the boundaries not of the insides of the circles. To convert our circle polygons to just the outlines we use st_cast("LINESTRING").
circles <- centers |>
# we use the distance from each center
# this is stored in km so we multiply by 1000 to get meters
st_buffer(dist=centers$Distance*1000) |>
# get just the outline of the cirles
st_cast("LINESTRING")
## Warning in st_cast.sf(st_buffer(centers, dist = centers$Distance * 1000), :
## repeating attributes for all sub-geometries for which they may not be constant
leaflet() |>
addTiles() |>
# we use the color column defined earlier
addPolylines(data=circles, color=~color, popup=~brk_name) |>
addMarkers(data=centers)
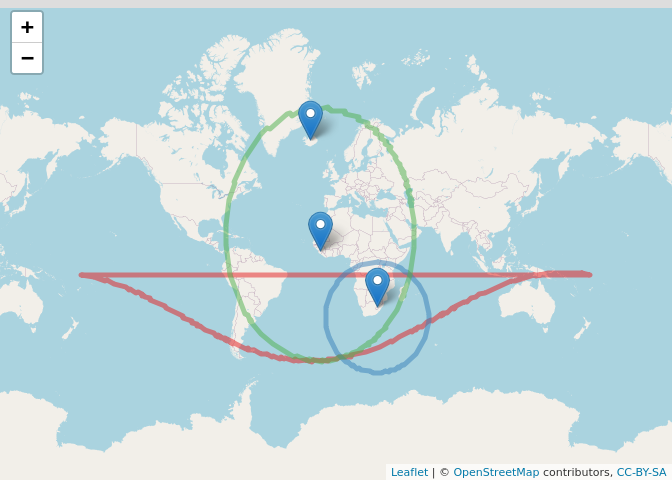
Circles extending from the centers of each country showing the distance from each to the correct country. The correct country should be located where all three circles intersect. Notice the red circle is misshapen because it is for Iceland which has a very large radius and is near the north pole. For our purposes, we only care about the lower half of it. The back half can be thought of as extending around the other side of the globe.
The circle for Iceland, in red, is only displayed as a semicircle. This is due to its radius being so large and extending over the north pole. Fortunately, that doesn’t matter for our purposes. By looking where the three circles intersect we should be able to find the country we are searching for.
With triangulation, the three circles will intersect in just one spot. It may appear that all three circles intersect in two places, but this is an artifact of the circle around Iceland being weirdly displayed.
To find where all the circles intersect we find any intersection amongst them with st_intersection() then narrow down the resulting points to those that have three or more overlaps.
This means we should focus our search at (3.4838,-54.7352). Since the measurements are not exact we look for this point on a map plus a little extra to help us see what’s around it.
leaflet() |>
addTiles() |>
addCircles(data=overlaps) |>
# 100 km search area
addPolylines(data=overlaps |> st_buffer(dist=100*1000))
The point where all the circles intersect with a 100 km buffer for he search area.
And we found Bouvet Island! This little uninhabited nature reserve isn’t even in the data.frame provided by {rnaturalearth} so I’m not sure how I would have found it without {sf}.
Spatial analytics and GIS are a really powerful part of data science and I have been using them more and more for clients lately. I’ve also given a coupletalks recently where you can see more about GIS.
While Worldle is fun to play on its own, it was even more fun using R to find the solution for a particularly tricky problem.
We are so excited to bring back the fourth annual Government and Public Sector R Conference to a computer screen near you! Join us on December 9th and 10th for a jam-packed two-day conference filled with an incredible lineup of speakers across the government and public sector space.
Introduction to Machine Learning for Public Policy with Jonathan Hersh
Alexandra, one of my former students, plans to take you through data analysis on climate change, by exploring publicly available datasets that you may or may not have known about. As Alexandra describes it, “by the end of the day, attendees should have a working knowledge of how the data support the science, and where to gather data and information about specific climate change issues they may face in their work.”
If a workshop on climate change is not right for you, my close friend Jonathan Hersh is giving his workshop on machine learning for public policy. Jonathan will lead you through applied machine learning exercises with a focus on the public space. The session will cover basic concepts like supervised vs. unsupervised learning, testing and training sets, and the bias-variance tradeoff. Jonathan will also review linear regression, ridge regression, cross-validation, and lasso regression. He will cover R Language and syntax, data manipulation in R, exploratory data analysis, and basic plotting in R.
The aRt auction is back! The auction features pieces by artists from the R Community. All proceeds will be donated to the R Foundation, a not-for-profit organization committed to the continued development of R. Bidding will begin December 1st and winners will be announced December 10th in the afternoon during the conference!
I would like to extend a special thank you to my good friend, Marck Vaisman and the Data Community DC. This conference would not be possible without your continued support. And I thank you, Marck, for our close friendship over the years. It has been incredible to witness the growth of the meetup community right alongside you.
The additional support of RStudio, PolicyViz, the R Consortium and Pearson goes a long way to making this conference such an informative and fun event.
In previous posts I talked about collecting temperature data from different rooms in my house and automating that process using Docker and GitHub Actions. Now it is time to analyze that data to figure out what is happening in the house to make informed decisions about replacing the HVAC units and how I can make the house more comfortable for everyone until then.
During this process I pull the data into R from a DigitalOcean space (like an AWS S3 bucket) using {arrow}, manipulate the data with {dplyr}, {tidyr} and {tsibble}, visualize the data with {timetk}, fit models with {fable} and visualize the models with {coefplot}.
Getting the Data
As discussed in the post about tracking the data, we created a CSV for each day of data in a DigitalOcean space. The CSV tracks room temperatures, thermostat settings, outdoor temperature, etc for every five-minute interval during each day.
In the past, if multiple files had to be read into a single data.frame or tibble the best course of action would have been to combine map_df() from {purrr} with read_csv() or fread() from {readr} and {data.table}, respectively. But as seen in Wes McKinney and Neal Richardson’stalk from the 2020 New York R Conference, using open_data() from {arrow} then collecting the data with dplyr::collect()should be faster. An added bonus is that {arrow} has functionality built in to pull from an S3 bucket, and that includes DigitalOcean spaces.
The first step is to use arrow::S3FileSystem$create() to make a reference to the S3 file system. Several pieces of information are needed for this:
endpoint_override: Since we are using DigitalOcean and not AWS we need to change the default to something along the lines of "nyc3.digitaloceanspaces.com", depending on the region.
The Access Key can be retrieved at any time, but the Secret Key is only displayed one time, so we must save it somewhere.
This is all the same information used when writing the files to the DigitalOcean space in the first place. We also save it all in environment variables in the .Renviron file to avoid exposing this sensitive information in our code. It is very important to not check this file into git to reduce risk of exposing the private keys.
space <- arrow::S3FileSystem$create(
access_key=Sys.getenv('AWS_ACCESS_KEY_ID'),
secret_key=Sys.getenv('AWS_SECRET_ACCESS_KEY'),
scheme="https",
endpoint_override=glue::glue("{Sys.getenv('DO_REGION')}.{Sys.getenv('DO_BASE')}")
)
space
## S3FileSystem
The space object represents the S3 file system we have access to. Its elements are mostly file system type functions such as cd()ls(), CopyFile() and GetFileInfo() and are accessed via space$function_name(). To see a listing of files in a folder inside a bucket we call space$ls() with the bucket and folder name as the argument, in quotes.
To use open_dataset() we need a path to the folder holding the files. This is built with space$path(). The structure is "bucket_name/folder_name". For security, even the bucket and folder names are stored in environment variables. For this example, the real values have been substituted with "bucket_name" and "folder_name".
Now we can call open_dataset() to get access to all the files in that folder. We need to specify format="csv" to let the function know the files are CSVs as opposed to parquet or other formats.
Printing out the temps_dataset object shows the column names along with the type of data stored in each column. {arrow} is pretty great and lets us do column selection and row filtering on the data sitting in files which opens up a whole world of data analysis on data too large to fit in memory. We are simply going to select columns of interest and collect all the data into one data.frame (actually a tibble). Notice we call select() before collect() because this reduces the number of columns being transmitted over the network.
library(dplyr)
temps_raw %>% head()
## # A tibble: 6 x 16
## Name Sensor date time temperature fan zoneAveTemp HVACmode
## <chr> <chr> <date> <chr> <dbl> <int> <dbl> <chr>
## 1 Upst… Bedro… 2021-01-01 00:0… 67.8 300 70 heat
## 2 Upst… Bedro… 2021-01-01 00:0… 72.4 300 70 heat
## 3 Upst… Offic… 2021-01-01 00:0… NA 300 70 heat
## 4 Upst… Upsta… 2021-01-01 00:0… 63.1 300 70 heat
## 5 Upst… Offic… 2021-01-01 00:0… NA 300 70 heat
## 6 Upst… Offic… 2021-01-01 00:0… NA 300 70 heat
## # … with 8 more variables: outdoorTemp <dbl>, outdoorHumidity <int>, sky <int>,
## # wind <int>, zoneClimate <chr>, zoneHeatTemp <dbl>, zoneCoolTemp <dbl>,
## # zoneHVACmode <chr>
Preparing the Data
The data are in need of some minor attention. First, the time column is read in as a character instead of time. This is a known issue, so instead we combine it with the date column using tidyr::unite() then convert this combination into a datetime (or timestamp) with lubridate::as_datetime(), which requires us to set a time zone. Then, the sensors named Upstairs Thermostat and Downstairs Thermostat actually represent Bedroom 3 and Dining Room, respectively, so we rename those using case_when() from {dplyr}, leaving all the other sensor names as is. Then we only keep rows where the time is earlier than the present. This is due to a quirk of the Ecobee API where it can return future readings, which happens because we request all of the latest day’s data.
Since the actual data may contain sensitive information a sanitized version is stored as parquet files on a public DigitalOcean space. This dataset is not as up to date but it will do for those that want to follow along.
publicspace <- arrow::S3FileSystem$create(
# anonymous means we do not need to provide credentials
# is crucial, otherwise the function looks for credentials
anonymous=TRUE,
# and crashes R if it can't find them
scheme="https",
# the data are stored in the nyc3 region
endpoint_override='nyc3.digitaloceanspaces.com'
)
publicspace$ls('temperaturedata', recursive=TRUE)
## # A tibble: 6 x 15
## Name Sensor time temperature fan zoneAveTemp HVACmode
## <chr> <chr> <dttm> <dbl> <int> <dbl> <chr>
## 1 Upst… Bedro… 2021-01-01 00:00:00 67.8 300 70 heat
## 2 Upst… Bedro… 2021-01-01 00:00:00 72.4 300 70 heat
## 3 Upst… Offic… 2021-01-01 00:00:00 NA 300 70 heat
## 4 Upst… Bedro… 2021-01-01 00:00:00 63.1 300 70 heat
## 5 Upst… Offic… 2021-01-01 00:00:00 NA 300 70 heat
## 6 Upst… Offic… 2021-01-01 00:00:00 NA 300 70 heat
## # … with 8 more variables: outdoorTemp <dbl>, outdoorHumidity <int>, sky <int>,
## # wind <int>, zoneClimate <chr>, zoneHeatTemp <dbl>, zoneCoolTemp <dbl>,
## # zoneHVACmode <chr>
Visualizing with Interactive Plots
The first step in any good analysis is visualizing the data. In the past, I would have recommended {dygraphs} but have since come around to {feasts} from Rob Hyndman’s team and {timetk} from Matt Dancho due to their ease of use, better flexibility with data types and because I personally think they are more visually pleasing.
In order to show the outdoor temperature on the same footing as the sensor temperatures, we select the pertinent columns with the outdoor data from the tempstibble and stack them at the bottom of temps, after accounting for duplicates (Each sensor has an outdoor reading, which is the same across sensors).
all_temps <- dplyr::bind_rows(
temps,
temps %>%
dplyr::select(Name, Sensor, time, temperature=outdoorTemp) %>%
dplyr::mutate(Sensor='Outdoors', Name='Outdoors') %>%
dplyr::distinct()
)
Then we use plot_time_series() from {timetk} to make a plot that has a different colored line for each sensor and for the outdoors (with sensors being grouped into facets according to which thermostat they are associated with). Ordinarily the interactive version would be better (.interactive=TRUE below), but for the sake of this post static displays better.
From this we can see a few interesting patterns. Bedroom 1 is consistently higher than the other bedrooms, but lower than the offices which are all on the same thermostat. All the downstairs rooms see their temperatures drop overnight when the thermostat is lowered to conserve energy. Between February 12 and 18 this dip was not as dramatic, due to running an experiment to see how raising the temperature on the downstairs thermostat would affect rooms on the second floor.
Computing Cross Correlations
One room in particular, Bedroom 2, always seemed colder than all the rest of the rooms, so I wanted to figure out why. Was it affected by physically adjacent rooms? Or maybe it was controlled by the downstairs thermostat rather than the upstairs thermostat as presumed.
So the first step was to see which rooms were correlated with each other. But computing correlation with time series data isn’t as simple because we need to account for lagged correlations. This is done with the cross-correlation function (ccf).
In order to compute the ccf, we need to get the data into a time series format. While R has extensive formats, most notably the built-in ts and its extension xts by Jeff Ryan, we are going to use tsibble, from Rob Hyndman and team, which are tibbles with a time component.
The tsibble object can treat multiple time series as individual data and this requires the data to be in long format. For this analysis, we want to treat multiple time series as interconnected, so we need to put the data into wide format using pivot_wider().
wide_temps <- all_temps %>%
# we only need these columns
select(Sensor, time, temperature) %>%
# make each time series its own column
tidyr::pivot_wider(
id_cols=time,
names_from=Sensor,
values_from=temperature
) %>%
# convert into a tsibble
tsibble::as_tsibble(index=time) %>%
# fill down any NAs
tidyr::fill()
wide_temps
## # A tibble: 15,840 x 12
## time `Bedroom 2` `Bedroom 1` `Office 1` `Bedroom 3` `Office 3`
## <dttm> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2021-01-01 00:00:00 67.8 72.4 NA 63.1 NA
## 2 2021-01-01 00:05:00 67.8 72.8 NA 62.7 NA
## 3 2021-01-01 00:10:00 67.9 73.3 NA 62.2 NA
## 4 2021-01-01 00:15:00 67.8 73.6 NA 62.2 NA
## 5 2021-01-01 00:20:00 67.7 73.2 NA 62.3 NA
## 6 2021-01-01 00:25:00 67.6 72.7 NA 62.5 NA
## 7 2021-01-01 00:30:00 67.6 72.3 NA 62.7 NA
## 8 2021-01-01 00:35:00 67.6 72.5 NA 62.5 NA
## 9 2021-01-01 00:40:00 67.6 72.7 NA 62.4 NA
## 10 2021-01-01 00:45:00 67.6 72.7 NA 61.9 NA
## # … with 15,830 more rows, and 6 more variables: `Office 2` <dbl>, `Living
## # Room` <dbl>, Playroom <dbl>, Kitchen <dbl>, `Dining Room` <dbl>,
## # Outdoors <dbl>
Some rooms’ sensors were added after the others so there are a number of NAs at the beginning of the tracked time.
We compute the ccf using CCF() from the {feasts} package then generate a plot by piping that result into autoplot(). Besides a tsibble, CCF() needs two arguments, the columns whose cross-correlation is being computed.
The negative lags are when the first column is a leading indicator of the second column and the positive lags are when the first column is a lagging indicator of the second column. In this case, Living Room seems to follow Bedroom 2 rather than lead.
We want to compute the ccf between Bedroom 2 and every other room. We call CCF() on each column in wide_temps against Bedroom 2, including Bedroom 2 itself, by iterating over the columns of wide_temps with map(). We use a ~ to treat CCF() as a quoted function and wrap .x in double curly braces to take advantage of non-standard evaluation. This creates a list of objects that can be plotted with autoplot(). We make a list of ggplot objects by iterating over the ccf objects using imap(). This allows us to use the name of each element of the list in ggtitle. Lastly, wrap_plots() from {patchwork} is used to show all the plots in one display.
library(patchwork)
library(ggplot2)
room_ccf <- wide_temps %>%
purrr::map(~CCF(wide_temps, {{.x}}, `Bedroom 2`))
# we don't want the CCF with time, outdoor temp or the Bedroom 2 itself
room_ccf$time <- NULL
room_ccf$Outdoors <- NULL
room_ccf$`Bedroom 2` <- NULL
biggest_cor <- room_ccf %>% purrr::map_dbl(~max(.x$ccf)) %>% max()
room_ccf_plots <- purrr::imap(
room_ccf,
~ autoplot(.x) +
# show the maximally cross-correlation value
# so it easier to compare rooms
geom_hline(yintercept=biggest_cor, color='red', linetype=2) +
ggtitle(.y) +
labs(x=NULL, y=NULL) +
ggthemes::theme_few()
)
wrap_plots(room_ccf_plots, ncol=3)
This brings up an odd result. Office 1, Office 2, Office 3, Bedroom 1, Bedroom 2 and Bedroom 3 are all controlled by the same thermostat, but Bedroom 2 is only really cross-correlated with Bedroom 3 (and negatively with Office 3). Instead, Bedroom 2 is most correlated with Playroom and Living Room, both of which are controlled by a different thermostat.
So it will be interesting to see which thermostat setting (the set desired temperature) is most cross-correlated with Bedroom 2. At the same time we’ll check how much the outdoor temperature cross-correlates with Bedroom 2 as well.
temp_settings <- all_temps %>%
# there is a column for outdoor temperatures so we don't need these rows
filter(Name != 'Outdoors') %>%
select(Name, time, HVACmode, zoneCoolTemp, zoneHeatTemp) %>%
# this information is repeated for each sensor, so we only need it once
distinct() %>%
# depending on the setting, the set temperature is in two columns
mutate(setTemp=if_else(HVACmode == 'heat', zoneHeatTemp, zoneCoolTemp)) %>%
tidyr::pivot_wider(id_cols=time, names_from=Name, values_from=setTemp) %>%
# get the reading data
right_join(wide_temps %>% select(time, `Bedroom 2`, Outdoors), by='time') %>%
as_tsibble(index=time)
temp_settings
This plot makes a strong argument for Bedroom 2 being more affected by the downstairs thermostat than the upstairs like we presume. But I don’t think the downstairs thermostat is actually controlling the vents in Bedroom 2 because I have looked at the duct work and followed the path (along with a professional HVAC technician) from the furnace to the vent in Bedroom 2. What I think is more likely is that the rooms downstairs get so cold (I lower the temperature overnight to conserve energy), and there is not much insulation between the floors, so the vent in Bedroom 2 can’t pump enough warm air to compensate.
I did try to experiment for a few nights (February 12 and 18) by not lowering the downstairs temperature but the eyeball test didn’t reveal any impact. Perhaps a proper A/B test is called for.
Fitting Time Series Models with {fable}
Going beyond cross-correlations, an ARIMA model with exogenous variables can give an indication if input variables have a significant impact on a time series while accounting for autocorrelation and seasonality. We want to model the temperature in Bedroom 2 while using all the other rooms, the outside temperature and the thermostat settings to see which affected Bedroom 2 the most. We fit a number of different models then compare them using AICc (AIC corrected) to see which fits the best.
To do this we need a tsibble with each of these variables as a column. This requires us to join temp_settings with wide_temps.
ts_mods %>%
glance() %>%
# sort .model according to AICc for better plotting
mutate(.model=forcats::fct_reorder(.model, .x=AICc, .fun=sort)) %>%
# smaller is better for AICc
# so negate it so that the tallest bar is best
ggplot(aes(x=.model, y=-AICc)) +
geom_col() +
theme(axis.text.x=element_text(angle=25))
The best two models (as judged by AICc) are mod3 and mod1, some of the simpler models. The key thing they have in common is that Bedroom 1 is a predictor, which somewhat contradicts the findings from the cross-correlation function. We can examine mod3 by selecting it out of ts_mods then calling report().
This shows that Bedroom 1 and Bedroom 3 are significant predictors with SARIMA(3,1,2)(0,0,1) errors.
The third best model is one of the more complicated models, mod15. Not all the predictors are significant, though we should not judge a model, or the predictors, based on that.
What all these top performing models have in common is the inclusion of the other bedrooms as predictors.
While helping me interpret the data, my wife pointed out that all the colder rooms are on one side of the house while the warmer rooms are on the other side. That colder side is the one that gets hit by winds which are rather strong. This made me remember a long conversation I had with a very friendly and knowledgeable sales person at GasTec who said that wind can significantly impact a house’s heat due to it blowing away the thermal envelope. I wanted to test this idea, but while the Ecobee API returns data on wind, the value is always 0, so it doesn’t tell me anything. Hopefully, I can get that fixed.
Running Everything with {targets}
There were many moving parts to the analysis, so I managed it all with {targets}. Each step seen in this post is a separate target in the workflow. There is even a target to build an html report from an R Markdown file. The key is to load objects created by the workflow into the R Markdown document with tar_read() or tar_load(). Then tar_render() will figure out how the R Markdown document figures into the computational graph.
In addition to the R Markdown I made a shiny dashboard using the R Markdown flexdashboard format. I host this on RStudio Connect so I can get a live view of the data and examine the models. Besides from being a partner with RStudio, I really love this product and I use it for all of my internal reporting (and side projects) and we have a whole practice around getting companies up to speed with the tool.
What Comes Next?
So what can be done with this information? Based on the ARIMA model the other bedrooms on the same floor are predictive of Bedroom 2, which makes sense since they are controlled by the same thermostat. Bedroom 3 is consistently one of the coldest in the house and shares a wall with Bedroom 2, so maybe that wall could use some insulation. Bedroom 1 on the other hand is the hottest room on that floor, so my idea is to find a way to cool off that room (we sealed the vents with magnetic covers), thus lowering the average temperature on the floor, causing the heat to kick in, raising the temperature everywhere, including Bedroom 2.
The cross-correlation functions also suggest a relationship with Playroom and Living Room, which are some of the colder rooms downstairs and the former is directly underneath Bedroom 2. I’ve already put caulking cord in the gaps around the floorboards in the Playroom and that has noticeably raised the temperature in there, so hopefully that will impact Bedroom 2. We already have storm windows on just about every window and have added thermal curtains to Bedroom 2, Bedroom 3 and the Living Room. My wife and I also discovered air billowing in from around, not in, the fireplace in the Living Room, so if we can close that source of cold air, that room should get warmer then hopefully Bedroom 2 as well. Lastly, we want to insulate between the first floor ceiling and second floor.
While we make these fixes, we’ll keep collecting data and trying new ways to analyze it all. It will be interesting to see how the data change in the summer.
These three posts were intended to show the entire process from data collection to automation (what some people are calling robots) to analysis, and show how data can be used to make actionable decisions. This is one more way I’m improving my life with data.
In a recent post I talked about collecting temperature data from different rooms in my house. Using {targets}, I am able to get temperature readings for any given day down to five-minute increments and store that data on a DigitalOcean space.
Since I want to be able to both fit models on the data and track temperatures close to real time I needed this to run on a regular basis, say every 30-60 minutes. I have a machine learning server that Kaz Sakamoto, Michael Beigelmacher and I built from parts we bought and a collection of Raspberry Pis, but I didn’t want to maintain the hardware for this, I wanted something that was handled for me.
Luckily GitHub Actions can run arbitrary code on a schedule and provides free compute for public repositories. So I built a Docker image and GitHub Actions configuration files to make it all happen. This all is based on the templogging repository on GitHub.
Docker Image
To ensure everything works as expected and to prevent package updates from breaking code, I used a combination of {renv} and Docker.
{renv} allows each individual project to have its own set of packages isolated from all other projects’ packages. It also keeps track of package versions so that the project can be restored on other computers, or in a Docker container, in the exact same configuration.
Using {renv} is fairly automatic. When starting a new project run renv::init() to create the isolated package library and start tracking packages. Then packages are installed as usual with install.packages() or renv::install(). Then renv::snapshot() is periodically used to write the specific package versions to the renv.lock file which is saved in the root directory of the project.
Docker is like a lightweight virtual machine that can create a specific environment. For this project I wanted a specific version of R (4.0.3), a handful of system libraries like libxml2-dev (for {igraph}, which is needed for {targets}) and libcurl4-openssl-dev (for {httr}) and all of the packages tracked with {renv}.
The R version is provided by starting with the corresponding r-ver image from the rocker project. The system libraries are installed using apt install.
The R packages are installed using renv::restore() but this requires files from the project to be added to the image in the right order. First, the templogging directory is created to hold everything, then individual files needed for the project and {renv} are added to that directory: templogging.Rproj, .Rprofile and renv.lock. Then the entire renv directory is added as well. After that, the working directory is changed to the templogging directory so that the following commands take place in that location.
Then comes time to install all the packages tracked in renv.lock. This is done with RUN Rscript -e "renv::restore(repos='https://packagemanager.rstudio.com/all/__linux__/focal/latest', confirm=FALSE)". Rscript -e runs R code as if it were executed in an R session. renv::restore() installs all the specific packages. Setting repos='https://packagemanager.rstudio.com/all/__linux__/focal/latest' specifies to use prebuilt binaries from the publicRStudio Package Manager (some people need the commercial, private version and if you think this may be you, my company, Lander Analytics can help you get started).
After the packages are installed, the rest of the files in the project are copied into the image with ADD . /templogging. It is important that this step takes place after the packages are installed so that changes to code does not trigger a reinstall of the packages.
FROM rocker/r-ver:4.0.3
# system libraries
RUN apt update && \
apt install -y --no-install-recommends \
# for igraph
libxml2-dev \
libglpk-dev \
libgmp3-dev \
# for httr
libcurl4-openssl-dev \
libssl-dev && \
# makes the image smaller
rm -rf /var/lib/apt/lists/*
# create project directory
RUN mkdir templogging
# add some specific files
ADD ["templogging.Rproj", ".Rprofile", "renv.lock", "/templogging/"]
# add all of the renv folder, except the library which is marked out in .dockerignore
ADD renv/ /templogging/renv
# make sure we are in the project directory so restoring the packages works cleanly
WORKDIR /templogging
# this restores the desired packages (including specific versions)
# it uses the public RStudio package manager to get binary versions of the packages
# this is for faster installation
RUN Rscript -e "renv::restore(repos='https://packagemanager.rstudio.com/all/__linux__/focal/latest', confirm=FALSE)"
# then we add in the rest of the project folder, including all the code
# we do this separately so that we can change code without having to reinstall all the packages
ADD . /templogging
To make building and running the image easier I made a docker-compose.yml file.
Now the image is available to be used anywhere. Since this image, and all the code are public, it’s important that nothing personal or private was saved in the code. As can be seen in the docker-compose.yml file or any of the R code in the repo, all potentially sensitive information was stored in environment variables.
The {targets} workflow can be executed inside the Docker container with the following shell command.
docker-compose run templogging R -e "targets::tar_make()"
That will get and write data for the current date. To run this for a specific date, a variable called process_date should be set to that date (assumes the TZ environment variable has been set) and tar_make() should be called with the callr_function argument set to NULL. I’m sure there is a better way to set arguments to make tar_make() of runtime settings, but I haven’t figured it out yet.
docker-compose run templogging R -e "process_date <- as.Date('2021-02-20')" -e "targets::tar_make(callr_function=NULL)"
GitHub Actions
After the Docker image was built, I automated the whole process using GitHub Actions. This requires a yml file inside the .github/workflows folder in the repository.
The first section is on:. This tells GitHub to run this job whenever there is a push to the main or master branch and whenever there is a pull request to these branches. It also runs every 30 minutes thanks to the schedule block that has - cron: '*/30 * * * *'. The */30 means “every thirty” and it’s the first position which means minutes (0-59). The second position would be hours (0-23). The following positions are day of month (1-31), month of year (1-12), day of the week (1-7, with 1 as Monday) and year (1900-3000).
The next section, name:, just provides the name of the workflow.
Then comes the jobs: section. Multiple jobs can be run, but there is only one job called Run-Temp-Logging.
The job runs on (runs-on:) ubuntu-latest as opposed to Windows or macOS.
This is going to use the Docker container so the container: block specifies an image: and environment variables (env:). The environment variables are stored securely in GitHub and are accessed via ${{ secrets.VARIABLE_NAME }}. Since I created this I have been debating if it would be faster to install the packages directly in the virtual machine spun up by the actions runner than to use a Docker image. Given that R package installations can be cached it might work out, but I haven’t tested it yet.
The steps: block runs the {targets} workflow. There can be multiple steps, though in this case there is only one, so each starts with a dash (-). For the step, a name: is given, along with what to run (run: R -e "targets::tar_make()") and the working directory (working-directory: /templogging), each on a separate line in the file. The R -e "targets::tar_make()" command runs in the Docker container with /templogging as the working directory. This has the same result as running docker-compose run templogging R -e "targets::tar_make()" locally. Each time this is run the file in the DigitalOcean space gets written anew.
With this running every 30 minutes I can pull the data just about any time and have close-enough-to-live insight into my house. But let’s be honest, I really only need to see up to the past few days to make sure everything is all right, so a 30-minute delay is more than good enough.
End of Day
While the job is scheduled to run every thirty minutes, I noticed that it wasn’t exact, so I couldn’t be sure I would capture the last few five-minute intervals of each day. So I made another GitHub Action to pull the prior day’s data at 1:10 AM.
The instructions are mostly the same with just two changes. First, the schedule is - cron: '10 1 * * *' which means on the 10th minute of the first hour. Since the rest of the slots are * the job occurs on every one of them, so it is the 10th minute of the first hour of every day of every month of every year.
The second change is the command given to the Docker container to run the {targets} workflow. As alluded to earlier, the _targets.R file is designed so that if Process_date is assigned a date, the data will be pulled for that date instead of the current date. So the run: portion has the command R -e "Sys.setenv(TZ='${{ secrets.TZ }}')" -e "process_date <- Sys.Date() - 1" -e "targets::tar_make(callr_function=NULL)". This makes sure the timezone environment variable is set in R, process_date gets the value of the prior day’s date and tar_make() is called.
Now that the data are being collected it’s time to analyze and see what is happening in the house. This is very involved so that will be the subject of the next post.
My R-using family have a very old house with uneven heating and cooling. We are going to replace the HVAC system soon and rather than just install a new system I wanted to make data-driven decisions about the replacement. Since I have a couple of ecobee Thermostats which have remote sensors, I figured there must be an API I can use to track the temperature in various rooms of the house.
A quick search turned up an API that was even better than I hoped. My initial plan was to call the API every five minutes and write the data to a database, either self hosted or managed by DigitalOcean. This would require my code to never miss a run because it would only capture the status at that moment, which also meant not being able to go back in time to correct things. Fortunately, the API can also give historic data for any period of time in five-minute increments and this is much more useful.
In this post I will go through the process of calling the API, storing the data and building a workflow using {targets}. In the next post I’ll cover automating the process using GitHub Actions. In the third post I’ll show how I analyzed the data using time series methods.
Accessing the API
Before we can use the API we need to sign up for a key, and have an ecobee thermostat, of course. Getting the API key is explained here, though last I checked we cannot complete the process with two factor authentication (2FA) turned on, so we should disable 2FA, register for the API, then re-enable 2FA.
Using the API requires the API key and an access token, but the access token only lasts for one hour. So we are given a refresh token, which is good for a year, and can be used to get a new access token. There is probably a better way to build the URL for {httr}, but this worked. Both the refresh token and API key will be strings of letters, numbers and symbols along the lines of ha786234h1q763h.
token_request <- httr::POST(
# it uses the token endpoint with parameters in the URL
url="https://api.ecobee.com/token?grant_type=refresh_token&code=ha786234h1q763h&client_id=kjdf837hw7384",
encode='json'
)
access_token <- httr::content(token_request)$access_token
Next, we use the API to get information about our thermostats, particularly the IDs and the current times. The access token is used for bearer authentication, which is added as a header to the httr::get() call. All API requests from now on will need this access token.
thermostat_info <- httr::GET(
# the requesting URL
# the request is to the thermostat endpoint with parameters passes in a json body that is part of the URL
# location is needed for the timezone offset
'https://api.ecobee.com/1/thermostat?format=json&body={"selection":{"selectionType":"registered","selectionMatch":"","includeLocation":true}}'
# authentication header
# supplying a header with "Bearer access_token" tells the API who we are
, httr::add_headers(Authorization=glue::glue('Bearer {access_token}'))
# json is the chosen format
, encode='json'
) %>%
# extract the contact into a list
httr::content()
From this object we can get the thermostat IDs which will be useful for generating the report.
thermostat_ids <- thermostat_info$thermostatList %>%
purrr::map_chr('identifier') %>%
# make it a single-element character vector that separates IDs with a comma
paste(collapse=',')
thermostat_ids
## [1] "28716,17611"
Given thermostat IDs we can request a report for a given time period. The report requires a startDate and endDate. By default the returned data are from midnight to 11:55 PM UTC. So a startInterval and endInterval shifts the time to the appropriate time zone which can be ascertained from thermostat_info$thermostatList[[1]]$location$timeZoneOffsetMinutes.
First thing to note is that the intervals are in groups of five minutes, so in a 24-hour day there are 288 intervals. We then account for being east or west of UTC, and subtract out a fifth of the offset. The endInterval is just one less than this startInterval in order to completely wrap around the clock. Doing these calculations should get us the entire day in our time zone.
Now we build the request URL for the report. The body in the URL takes a number of parameters. We already have startDate, endDate, startInterval and endInterval. columns is a comma separated listing of the desired data points. For our purposes we want "zoneAveTemp,hvacMode,fan,outdoorTemp,outdoorHumidity,sky,wind,zoneClimate,zoneCoolTemp,zoneHeatTemp,zoneHvacMode,zoneOccupancy". The selection parameter takes two arguments: selectionType, which should be "thermostats" and selectionMatch, which is the comma-separated listing of thermostat IDs saved in thermostat_ids. We want data from the room sensors so we set includeSensors to true. Like in previous requests, this URL is built using glue::glue().
report <- httr::GET(
glue::glue(
# the request is to the runtimeReport endpoint with parameters passes in a json body that is part of the URL
'https://api.ecobee.com/1/runtimeReport?format=json&body={{"startDate":"{startDate}","endDate":"{endDate}","startInterval":{startInterval},"endInterval":{endInterval},"columns":"zoneAveTemp,hvacMode,fan,outdoorTemp,outdoorHumidity,sky,wind,zoneClimate,zoneCoolTemp,zoneHeatTemp,zoneHvacMode,zoneOccupancy","selection":{{"selectionType":"thermostats","selectionMatch":"{thermostats}"}},"includeSensors":true}}'
)
# authentication
, httr::add_headers(Authorization=glue::glue('Bearer {access_token}'))
, encode='json'
) %>%
httr::content()
Handling the Data
Now that we have the report object we need to turn it into a nice data.frame or tibble. There are two major components to the data: thermostat information and sensor information. Multiple sensors are associated with a thermostat, including a sensor in the thermostat itself. So if our house has two HVAC zones, and hence two thermostats, we would have two sets of this information. The thermostat information includes overall data such as date, time, average temperature (average reading for all the sensors associated with a thermostat), HVACMode (heat or cool), fan speed and outdoor temperature. The sensor information has readings from each sensor associated with each thermostat such as detected occupancy and temperature.
The thermostat level and sensor level data are kept in lists inside the report object and need to be handled separately.
Thermostat Level Data
The report object has an element called reportList, which is a list where each element represents a different thermostat. For a house with two thermostats this list will have a length of two. Each of these elements contains a list called rowList. This has as many elements as the number of intervals requested, 288 for a full day (five-minute intervals for 24 hours). All of these elements are charactervectors of length one, with commas separating the values. A few examples are below.
Perhaps a lesser known feature of readr::read_csv() is that rather than a file, it can read a charactervector where each element has comma-separated values and return a tibble.
library(magrittr)
library(readr)
report$reportList[[1]]$rowList %>%
unlist() %>%
# add date and time to the specified column names
read_csv(col_names=c('date', 'time', strsplit(report$columns, split=',')[[1]]))
date
time
zoneAveTemp
HVACmode
fan
outdoorTemp
outdoorHumidity
sky
wind
zoneClimate
zoneCoolTemp
zoneHeatTemp
zoneHVACmode
zoneOccupancy
2021-01-25
00:00:00
70.5
heat
75
28.4
43
5
0
Sleep
71
71
heatOff
0
2021-01-25
00:05:00
70.3
heat
300
28.4
43
5
0
Sleep
71
71
heatStage1On
0
2021-01-25
00:10:00
70.2
heat
300
28.4
43
5
0
Sleep
71
71
heatStage1On
0
2021-01-25
00:15:00
70.2
heat
300
28.4
43
5
0
Sleep
71
71
heatStage1On
0
2021-01-25
00:20:00
70.3
heat
300
28.4
43
5
0
Sleep
71
71
heatStage1On
0
We repeat that for each element in report$reportList and we have a nice tibble with the data we need.
library(purrr)
##
## Attaching package: 'purrr'
## The following object is masked from 'package:magrittr':
##
## set_names
# using the thermostat IDs as names let's them be identified in the tibble
names(report$reportList) <- purrr::map_chr(report$reportList, 'thermostatIdentifier')
central_thermostat_info <- report$reportList %>%
map_df(
~ read_csv(unlist(.x$rowList), col_names=c('date', 'time', strsplit(report$columns, split=',')[[1]])),
.id='Thermostat'
)
central_thermostat_info
Thermostat
date
time
zoneAveTemp
HVACmode
fan
outdoorTemp
outdoorHumidity
sky
wind
zoneClimate
zoneCoolTemp
zoneHeatTemp
zoneHVACmode
zoneOccupancy
28716
2021-01-25
00:00:00
70.5
heat
75
28.4
43
5
0
Sleep
71
71
heatOff
0
28716
2021-01-25
00:05:00
70.3
heat
300
28.4
43
5
0
Sleep
71
71
heatStage1On
0
28716
2021-01-25
00:10:00
70.2
heat
300
28.4
43
5
0
Sleep
71
71
heatStage1On
0
28716
2021-01-25
00:15:00
70.2
heat
300
28.4
43
5
0
Sleep
71
71
heatStage1On
0
28716
2021-01-25
00:20:00
70.3
heat
300
28.4
43
5
0
Sleep
71
71
heatStage1On
0
17611
2021-01-25
00:00:00
64.4
heat
135
28.4
43
5
0
Sleep
78
64
heatOff
0
17611
2021-01-25
00:05:00
64.2
heat
0
28.4
43
5
0
Sleep
78
64
heatOff
0
17611
2021-01-25
00:10:00
64.0
heat
0
28.4
43
5
0
Sleep
78
64
heatOff
0
17611
2021-01-25
00:15:00
63.9
heat
0
28.4
43
5
0
Sleep
78
64
heatOff
0
17611
2021-01-25
00:20:00
63.7
heat
0
28.4
43
5
0
Sleep
78
64
heatOff
0
Sensor Level Data
Due to the way the sensor data is stored they are more difficult to extract than the thermostat data.
First, we get the column names for the sensors. The problem is, this varies depending on how many sensors are associated with each thermostat and also the type of sensor. As of now there are three types: the thermostat itself, which measures occupancy, temperature and humidity and two kinds of remote sensors, both of which measure occupancy and temperature.
To do this we write two functions, one relates a sensor ID to a sensor name and the other joins in the result of the first function to match the column names listed in the columns element of each element in the sensorList part of the report.
relate_sensor_id_to_name <- function(sensorInfo)
{
purrr::map_df(
sensorInfo,
~tibble::tibble(ID=.x$sensorId, name=glue::glue('{.x$sensorName}_{.x$sensorType}'))
)
}
# see how it works
relate_sensor_id_to_name(report$sensorList[[1]]$sensors)
ID
name
rs:100:2
Bedroom 1_occupancy
rs:101:1
Master Bedroom_temperature
rs:101:2
Master Bedroom_occupancy
rs2:100:1
Office 1_temperature
rs2:100:2
Office 1_occupancy
rs2:101:1
Office 2_temperature
rs:100:1
Bedroom 1_temperature
rs2:101:2
Office 2_occupancy
ei:0:1
Thermostat Temperature_temperature
ei:0:2
Thermostat Humidity_humidity
ei:0:3
Thermostat Motion_occupancy
make_sensor_column_names <- function(sensorInfo)
{
sensorInfo$columns %>%
unlist() %>%
tibble::enframe(name='index', value='id') %>%
dplyr::left_join(relate_sensor_id_to_name(sensorInfo$sensors), by=c('id'='ID')) %>%
dplyr::mutate(name=as.character(name)) %>%
dplyr::mutate(name=dplyr::if_else(is.na(name), id, name))
}
# see how it works
make_sensor_column_names(report$sensorList[[1]])
index
id
name
1
date
date
2
time
time
3
rs:100:2
Bedroom 1_occupancy
4
rs:101:1
Master Bedroom_temperature
5
rs:101:2
Master Bedroom_occupancy
6
rs2:100:1
Office 1_temperature
7
rs2:100:2
Office 1_occupancy
8
rs2:101:1
Office 2_temperature
9
rs:100:1
Bedroom 1_temperature
10
rs2:101:2
Office 2_occupancy
11
ei:0:1
Thermostat Temperature_temperature
12
ei:0:2
Thermostat Humidity_humidity
13
ei:0:3
Thermostat Motion_occupancy
Then for a set of sensors we can read the data from the data element using the read_csv() trick we saw earlier. Some manipulation is needed to we pivot the data longer, keep certain rows, break apart a column using tidyr::separate() make some changes with dplyr::mutate() then pivot wider.This results in a tibble, where each row represents the occupancy and temperature reading for a particular sensor and a given five-minute increment.
extract_one_sensor_info <- function(sensor)
{
sensor_col_names <- make_sensor_column_names(sensor)$name
sensor$data %>%
unlist() %>%
readr::read_csv(col_names=sensor_col_names) %>%
# make it longer so we can easy remove rows based on a condition
tidyr::pivot_longer(cols=c(-date, -time), names_to='Sensor', values_to='Reading') %>%
# we use slice because grep() returns a vector of indices, not TRUE/FALSE
dplyr::slice(grep(pattern='_(temperature)|(occupancy)$', x=Sensor, ignore.case=FALSE)) %>%
# split apart the sensor name from what it's measuring
tidyr::separate(col=Sensor, into=c('Sensor', 'Measure'), sep='_', remove=TRUE) %>%
# rename the actual thermostats to say thermostat
dplyr::mutate(Sensor=sub(pattern='Thermostat .+$', replacement='Thermostat', x=Sensor)) %>%
# back into wide format so each sensor is its own column
tidyr::pivot_wider(names_from=Measure, values_from=Reading)
}
# see how it works
extract_one_sensor_info(report$sensorList[[1]])
date
time
Sensor
occupancy
temperature
2021-01-25
00:00:00
Bedroom 1
0
69.5
2021-01-25
00:00:00
Master Bedroom
1
71.6
2021-01-25
00:00:00
Office 1
1
72.7
2021-01-25
00:00:00
Office 2
0
74.9
2021-01-25
00:00:00
Thermostat
0
65.8
2021-01-25
00:05:00
Bedroom 1
0
69.3
2021-01-25
00:05:00
Master Bedroom
1
71.3
2021-01-25
00:05:00
Office 1
0
72.5
2021-01-25
00:05:00
Office 2
0
74.8
2021-01-25
00:05:00
Thermostat
0
65.7
2021-01-25
00:10:00
Bedroom 1
0
69.2
2021-01-25
00:10:00
Master Bedroom
0
71.2
2021-01-25
00:10:00
Office 1
0
72.5
2021-01-25
00:10:00
Office 2
0
74.8
2021-01-25
00:10:00
Thermostat
0
65.6
2021-01-25
00:15:00
Bedroom 1
0
69.2
2021-01-25
00:15:00
Master Bedroom
1
71.2
2021-01-25
00:15:00
Office 1
0
72.5
2021-01-25
00:15:00
Office 2
0
74.8
2021-01-25
00:15:00
Thermostat
0
65.5
2021-01-25
00:20:00
Bedroom 1
0
69.4
2021-01-25
00:20:00
Master Bedroom
1
71.2
2021-01-25
00:20:00
Office 1
0
72.7
2021-01-25
00:20:00
Office 2
0
74.9
2021-01-25
00:20:00
Thermostat
0
65.4
Then we put it all together and iterate over the sets of sensors attached to each thermostat.
We now save all of the sensor information in sensor_info.
sensor_info <- extract_sensor_info(report)
Combining Sensor and Thermostat Data
To nicely align the thermostat overall readings and settings with the individual sensor readings, we join the two together using dplyr::left_join() with the Thermostat, date and time columns as keys. We also want to join in the nice thermostat names based on the thermostat IDs, so that tibble will need to be created first.
library(dplyr)
## Warning: package 'dplyr' was built under R version 4.0.3
##
## Attaching package: 'dplyr'
## The following objects are masked from 'package:stats':
##
## filter, lag
## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, union
We now have a nice tibble in long format where each row shows a number of measurements and setting for a sensor for a given period of time.
Saving Data in the Cloud
Now that we have the data we need to save it somewhere. Since these data should be more resilient, cloud storage seems like the best option. There are many services including Azure, AWS, BackBlaze and GCP. But I prefer to use DigitalOcean Spaces since it has an easy interface and can take advantage of standard S3 APIs.
DigitalOcean uses slightly different terminology than AWS, in that buckets are called spaces. Otherwise we still need to deal with Access Key IDs, Secret Access Keys, Regions and Endpoints. A good tutorial on creating DigitalOcean spaces comes directly from them. In fact, they have so many great tutorials about Linux in general, I highly recommend using them for learning so much about computing.
While there is a DigitalOcean package, aptly named {analogsea}, I did not have luck getting it to work, so instead I used {aws.s3}.
After writing the all_infotibble to a CSV, we put it to the DigitalOcean bucket using aws.s3::put_object(). This requires three arguments:
file: The name of the file on our computer.
object: The path including filename inside the S3 bucket where the file will be saved.
bucket: The name of the S3 bucket, or in our case the space (DigitalOcean calls buckets spaces).
Implicitly, put_object() and most of the functions in {aws.s3} depend on certain environment variables being set. The first two are AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY which correspond to the DigitalOcean Access Key and Secret Key, respectively. These can be generated at https://cloud.digitalocean.com/account/api/tokens. The Access Key can be retrieved at any time, but the Secret Key is only displayed one time, so we must save it somewhere. Just like AWS, DigitalOcean has regions and this value is saved in the AWS_DEFAULT_REGION environment variable. In this case the region is nyc3. Then we need the AWS_S3_ENDPOINT environment variable. The DigitalOcean documentation makes it seem like this should be nyc3.digitaloceanspaces.com (or the appropriate region) but for our purposes it should just be digitaloceanspaces.com.
Perhaps the most common way to set environment variables in R is to save them in the VARIABLE_NAME=value format in the .Renviron file either in our home directory or project directory. But we must be sure NOT to track this file with git lest we publicly expose our secret information.
Then we can call the put_object() function.
# we make a file each day so it is important to include the date in the name.
filename <- 'all_info_2021-02-15.csv'
aws.s3::put_object(
file=filename, object=sprintf('%s/%s', 'do_folder_name', filename), bucket='do_bucket_name'
)
After this, the file lives in a DigitalOcean space to be accessed later.
Putting it All Together with {targets}
There are a lot of moving parts to this whole process, even more so than displayed here. They could have all been put into a script but that tends to be fragile, so instead we use {targets}. This package, which is the eventual replacement for {drake}, builds a robust pipeline that schedules jobs to be run based on which jobs depend on others. It is intelligent in that it only runs jobs that are out of date (usually meaning neither the code nor data have been modified) and can run jobs in parallel. The author, Will Landau, gave an excellent talk about this at the New York Open Statistical Programming Meetup.
In order to use {targets}, we need to have a file named _targets.R in the root of our project. In there we have a list of targets, or jobs, each defined in a tar_target() function (or tar_force(), tar_change() or similar function). The first argument to tar_target() is the name of the target and the next argument is an expression, usually a function call, whose value is saved as the name.
A small example would be a target to get the access token, a target for getting thermostat information (which requires the access token), another to extract the thermostat IDs from that information and a last target to get the report based on the IDs and token.
With the _targets.R file in the root of the directory, we can visualize the steps with tar_visnetwork().
tar_visnetwork()
To execute the jobs we use tar_make().
tar_make()
The results of individual jobs, known as targets, can be loaded into the working session with tar_load(target_name) or assigned to a variable with variable_name <- tar_read(target_name).
Each time this is run the appropriate file in the DigitalOcean space either gets written for the first time, or overwritten.
The actual set of targets for this project were much more involved and can be found on GitHub. Each target is the result of a custom function, which allows for more thorough documentation and testing. The version on GitHub even allows us to run the workflow for different dates so we can backfill data if needed.
Please note that anywhere there is potentially sensitive information such as the refresh token or API key, those were saved in environment variables, then accessed via Sys.getenv(). It is very important not to check the .Renviron files, where environment variables are stored, into git. They should be treated like passwords.
What’s Next?
Now that we have a functioning workflow that we can call anytime, the question becomes how do we run this on a regular basis? We could set up a cron job on a server that requires the server to always be up and we need to maintain this process. We could use scheduled lambda functions, but that’s also a lot of work. Instead, we’ll use GitHub Actions to run this workflow on a scheduled basis. We’ll go over that in the next blog post.
The inaugural Government & Public Sector R Conference took place virtually from December 2nd to December 4th. With over 240 attendees, 26 speakers, three panelists and a rum masterclass class leader, the R|Gov conference was a place where data scientists could gather remotely to explore, share, and inspire ideas.
Check out some of the highlights from the conference:
Graciela Chichilnisky explains how financial instruments can resolve climate change
One of my former professors at Columbia University, Dr. Graciela Chichilnisky, gave a presentation on how financial instruments can resolve climate change quickly and effectively by using existing capital markets to benefit high—and, especially, low—income groups. The process Dr. Chichilnisky proposes is simple and can lead to a transformation of our capitalistic economy in the direction of human survival. Furthermore, it is realistic and is profitable. Dr. Chichilnisky acted as the lead U.S. author on the Intergovernmental panel on Climate Change, which received the 2007 Nobel Prize for its work in deciding world policy with respect to climate change, and she worked extensively on the Kyoto Protocol, creating and designing the carbon market that became international law in 2005.
Another classic no-slides talk from Andrew Gelman on how his team and The Economist Magazine built a presidential election forecasting model
Another professor of mine, Andrew Gelman told us he wanted to give a talk on how his team’s election forecasting succeeded brilliantly, failed miserably, or landed somewhere in between. To build the model, they combined national polls, state polls, and political and economic fundamentals. Because we didn’t know the results of the election at the time, he didn’t know which of the three he’d be talking about… So how did his election forecast perform? The model predicted 49 out of 50 states correctly… But that doesn’t mean the forecast was perfect… For some background, see this article.
Wendy Martinez inspires and shares lessons about the rocky road she traveled to using R at a U.S. Government agency
Wendy Martinez described some of her experiences — both successes and failures — using R at several U.S. government agencies. In addition to serving as the Director of the Mathematical Statistics Research Center at the Bureau of Labor Statistics (BLS) for the last eight years, she is currently the President of the American Statistical Association (ASA), and she also served in several research positions throughout the Department of Defense. She has also written two books on MATLAB! It’s nice to see that she switched to open source.
Colonel Alfredo Corbett Spoke On Air Combat Command Enterprise Data Improvements
Deputy Director of Communications of the United States Air Force Colonel Alfedo Corbett showed us why, in his work, data can be a warfighting asset, fundamental to how Air Combat Command (ACC) operates in—and supports—all domains of warfare. In coordination with the Department of Defense and the Department of the Air Force, ACC is working to improve its data governance, data architecture, data standards, and data talent & culture, implementing major improvements to the way it manages, acquires, ingests, stores, processes, exploits, analyzes, and delivers data to its almost 100,000 operators.
We Participated in Two Virtual Happy Hours!
At lunch on the first day of the conference, we took a dive into the history and distillation process of a legendary rum made at the longest continuously running distillery in the world, Mount Gay Brand Ambassador Darrio Prescod shared his knowledge and transported us to Barbados (where he tuned in from virtually). Following the second day of the conference, members of the Mount Gay brand development team took us through a rum tasting and shook up a couple of cocktails. Attendees and speakers listened and hung out, drinking rum, matcha, soda or water during our virtual happy hour.
All proceeds from the A(R)T Auction went to the R Foundation
We took an R-Ladies group [virtual] selfie. We would like to note that more R-Ladies participated, but chose not to share video.:
Jon Harmon, Selina Carter, Mayarí Montes de Oca & DiKayo Data win Raspberry Pis, Noise Cancelling Headphones, and Gaming Mechanical Keyboards for Most Active Tweeting You can see the R|Gov 2020 R Shiny Scoreboard here! A custom started at DCR 2018 by our Twitter scorekeeper Malorie Hughes (@data_all_day), has returned every year by popular demand. Congratulations to our winners!
52 Conference Attendees Participated in Pre-Conference Workshops
We ran the following workshops prior to the conference:
Geospatial Statistics and Mapping in R with Kaz Sakamoto
Introduction to Machine Learning for Public Policy with Jonathan Hersh
Moving from DCR to R|Gov With the shift to remote, we realized we could welcome a global audience to our annual conference, as we did for the virtual New York R Conference in August. And that gave birth to R|Gov, the Government and Public Sector R Conference. This new industry-focused conference focused on work in government, defense, NGOs and the public sector, and we have speakers from not only the DC-area, but also from Geneva, Switzerland, Nashville, Tennessee, Quebec, Canada and Los Angeles, California. For next year, we are working to invite speakers from more levels of government–local, state and federal. You can read more about this choice here.
Like NYR, R|Gov featured many in-person components of the gathering, like networking sessions, speaker walk-on songs and fun facts, happy hours, lots of giveaways, the Twitter contest, and the auction.
Thank you, Lander Analytics Team!
Even though it was virtual, there was a lot of work that went into the conference, and I want to thank my amazing team at Lander Analytics along with our producer, Bill Prickett, for making it all come together.
Looking Forward to New York, R|Gov, and Dublin!
If you attended, we hope you had an incredible experience. If you did not attend this year’s conference, we hope to see you at the at the New York R Conference and R|Gov in 2021, and, soon, the first Dublin R Conference.
My team at Lander Analytics has been putting together conferences for six years, and they’ve always had the same fun format, which the community has really enjoyed. There’s the NYR conference for New Yorkers and those who want to fly, drive or train to join the New York community, and there’s DCR, which gathers the DC-area community. The last DCR Conference at Georgetown University went really well, as you can see in this recap. With the shift to virtual gatherings brought on by the pandemic, our community has gone fully remote, including the monthly Open Statistical Programming Meetup. With that, we realized the DCR Conference didn’t just need to be for folks from the DC-area anymore, instead, we could welcome a global audience like we did with this year’s NYR. And that gave birth to R|Gov, the Government and Public Sector R Conference.
R|Gov is really a new industry-focused conference. Instead of drawing on speakers from a particular city or area, the talks will focus on work done in specific fields. In this case, in government, defense, NGOs and the public sector, and we have speakers from not only the DC-area, but also from Geneva, Switzerland, Nashville, Tennessee, Quebec, Canada and Los Angeles, California. For the last three years, we have been working with Data Community DC, R-Ladies DC, and the Statistical Programming DC Meetup, to put on DCR, and continue to do so for R|Gov as we find great speakers and organizations who want to collaborate in driving attendance and building the community.
Like NYR and DCR, the topics at R|Gov range from practical how-tos, to theoretical findings, to processes, to tooling and the speakers this year come from the Center for Army Analysis, NASA, Columbia University, The U.S. Bureau of Labor Statistics, the Inter-American Development Bank, The United States Census Bureau, Harvard Business School, In-Q-Tel, Virginia Tech, Deloitte, NYC Department of Health and Mental Hygiene and Georgetown University, among others. We will also be hosting two rum and gin master classes, including one with Mount Gay, which comes from the oldest continuously running rum distillery in the world, and which George Washington served at his inauguration!
The R Conference series is quite a bit different from other industry and academic conferences. The talks are twenty minutes long with no audience questions with the exception of special talks from the likes of Andrew Gelman or Hadley Wickham. Whether in person or virtual, we play music, have prize giveaways and involve food in the programming. When they were in person, we prided ourselves on avocado toast, pizza, ice cream and beer. For prizewinners, we autographed books right on stage since the authors were either speakers or in the audience. With the virtual events we try to capture as much of that spirit as possible, and the community really enjoyed the virtual R Conference | NY in August. A very lively event remotely and in the flesh, it is also one of the more informative conferences I have ever seen.
This virtual conference will include much of the in-person format, just recreated virtually. We will have 24 talks, a panel, workshops, community and networking breaks, happy hours, prizes and giveaways, a Twitter Contest, Meet the Speaker series, Job Board access, and participation in the Art Auction. We hope to see you there December 2-4, on a comfy couch near you.
The sixth annual (and first virtual) “New York” R Conference took place August 5-6 & 12-15. Almost 300 attendees, and 30 speakers, plus a stand-up comedian and a whiskey masterclass leader, gathered remotely to explore, share, and inspire ideas.
Let’s take a look at some of the highlights from the conference:
Andrew Gelman Gave Another 40-Minute Talk (no slides, as always)
Our favorite quotes from Andrew Gelman’s talk, Truly Open Science: From Design and Data Collection to Analysis and Decision Making, which had no slides, as usual:
“Everyone training in statistics becomes a teacher.”
“The most important thing you should take away — put multiple graphs on a page.”
“Honesty and transparency are not enough.”
“Bad science doesn’t make someone a bad person.”
Laura Gabrysiak Shows us We Are Driven By Experience, and not Brand Loyalty…Hope you Folks had a Good Experience!
Laura’s talk on re-Inventing customer engagement with machine learning went through several interesting use cases from her time at Visa. In addition to being a data scientist, she is an active community organizer and the co-founder of R-Ladies Miami.
Adam Obeng Delivered a Talk on Adaptive Experimentation
One of my former students at Columbia University, Adam Obeng, gave a great presentation on his adaptive experimentation. We learned that adaptive experimentation is three things: The name of (1) a family of techniques, (2) Adam’s team at Facebook, and (3) an open source package produced by said team. He went through the applications which are hyper-parameter optimization for ML, experimentation with multiple continuous treatments, and physical experiments or manufacturing.
Dr. Jacqueline Nolis Invited Us to Crash Her Viral Website, Tweet Mashup
Jacqueline asked the crowd to crash her viral website,Tweet Mashup, and gave a great talk on her experience building it back in 2016. Her website that lets you combine the tweets of two different people. After spending a year making it in .NET, when she launched the site it became an immediate sensation. Years later, she was getting more and more frustrated maintaining the F# code and decided to see if I could recreate it in Shiny. Doing so would require having Shiny integrate with the Twitter API in ways that hadn’t been done by anyone before, and pushing the Twitter API beyond normal use cases.
Attendees Participated in Two Virtual Happy Hours Packed with Fun
At the Friday Happy Hour, we had a mathematical standup comedian for the first time in R Conference history. Comic and math major Rachel Lander (no relationship to me!) entertained us with awesome math and stats jokes.
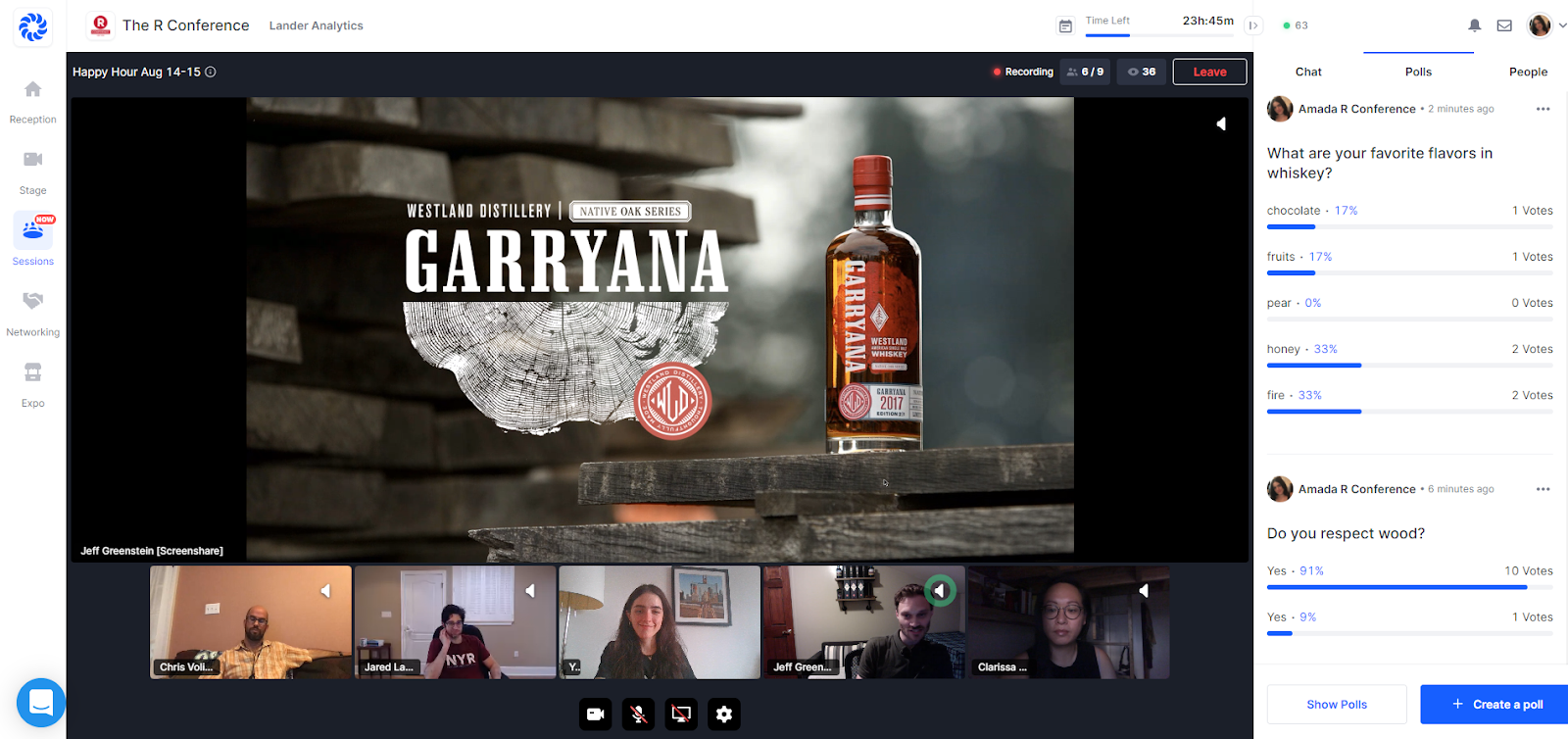
Following the stand up, we had a Whiskey Master Class with our Vibe Sponsor Westland Distillery, and another one on Saturday with Bruichladdich Distillery (hard to pronounce and easy to drink). Attendees and speakers learned and drank together, whether it be their whiskey, matchas, soda or water.
All Proceeds from the A(R)T Auction went to the R Foundation Again
A newer tradition, the A(R)T Auction, took place again! We featured pieces by artists in the R Community, and all proceeds were donated to the R Foundation. The highest-selling piece at auction was Street Cred (2020) by Vivian Peng (Lander Analytics and Los Angeles Mayor’s Office, Innovation Team). The second highest was a piece by Jacqueline Nolis (Brightloom, and Build a Career in Data Science co-author), R Conference speaker, Designed by Allison Horst, artist in residence at RStudio.
The R-Ladies Group Photo Happened, Even Remotely!
As per tradition, we took an R-Ladies group photo, but, for the first time, remotely– as a screenshot! We would like to note that many more R-Ladies were present in the chat, but just chose not to share video.
Jon Harmon, Edna Mwenda, and Jessica Streeter win Raspberri Pis, Bluetooth Headphones, and Tenkeyless Keyboards for Most Active Tweeting During the Conference
This year’s Twitter Contest, in Malorie’s words, was a “ruthless but noble war.” You can see the NYR 2020 Dashboard here. A custom started that DCR 2018 by our Twitter scorekeeper Malorie Hughes (@data_all_day) has returned every year by popular demand, and now she’s stuck with it forever! Congratulations to our winners!
50+ Conference Attendees Participated in Pre-Conference Workshops Before
For the first time ever, workshops took place over the course of several days to promote work-life balance, and to give attendees the chance to take more than one course. We ran the following seven workshops:
We recreated as much of the in-person experience as possible with attendee networking sessions, the speaker walk-on songs and fun facts, abundant prizes and giveaways, the Twitter contest, an art auction, and happy hours. In addition to all of this, we mailed conference programs, hex stickers, and other swag to each attendee (in the U.S.), along with discount codes from our Vibe Sponsors, MatchaBar, Westland Distillery and Bruichladdich Distillery.
Thank you, Lander Analytics Team!
Even though it was virtual, there was a lot of work that went into the conference, and I want to thank my amazing team at Lander Analytics along with our producer, Bill Prickett, for making it all come together.
Looking Forward to D.C. and Dublin If you attended, we hope you had an incredible experience. If you did not, we hope to see you at the virtual DC R Conference in the fall, and at the first Dublin R Conference and the NYR next year!
The Second Annual DCR Conference made its way to the ICC Auditorium at Georgetown University last week on November 8th and 9th. A sold-out crowd of R enthusiasts and data scientists gathered to explore, share and inspire ideas.
As always, the food was delicious! Our caterer even surprised us with Lander cookies.
Lander Analytics CookiesThe Excellent Buffet
David Robinson shared his Ten Tremendous Tricks in the Tidyverse. Always enthusiastic, DRob did a great job showing both well known and obscure functions for an easier data workflow.
DRobTen Tidyverse Tricks
Elizabeth Sweeney gave an awesome talk on Visualizing the Environmental Impact of Beef Consumption using Plotly and Shiny. We explored the impact of eating different cuts of beef in terms of the number of animal lives, Co2 emissions, water usage, and land usage. Did you know that there is a big difference in the environmental impact of consuming 100 pounds of hanger steak versus the same weight in ground beef? She used plotly to make interactive graphics and R Shiny to make an interactive webpage to explore the data.
Elizabeth Showing off Brains
The integrated development environment, RStudio, fully integrated themselves into the environment.
The RStudio Team
As a father, I’ve earned the right to make dad jokes (see above). You can see the slides for my talk, Raising Baby with R. While babies are commonly called bundles of joy, they are also bundles of data. Being the child of a data scientist and neuroscientist my son was certain to be analyzed myriad ways. I discussed how we used data to narrow down possible names then looked at using time series methods to analyze his sleeping and eating patterns. All in the name of science.
Talking Baby Data
Malorie Hughes Analyzing Tweets Again
We also organized a Tweeting competition with the help of Malorie Hughes, our Twitter scorekeeper. Check out the DCR 2019 Twitter Dashboard with the Mash-Up Metric Details she created.
Tweeting DashboardAs Usual, Emily was the Overall WinnerKim Won a Copy of my BookJon Really Worked Hard to Win These Headphones
There was a glitch in the system and one of our own organizers and former Python user won a prize. We let her keep it, and now she has no excuse not to learn R.
Amada, our Marketing Person, Won an R in Marketing Book
Not to mention we had some great workshops on November 7th, preceding the conference:
The costs involved with a health insurance plan can be confusing so I perform an analysis of different options to find which plan is most cost effective
My wife and I recently brought a new R programmer into our family so we had to update our health insurance. Becky is a researcher in neuroscience and psychology at NYU so we decided to choose an NYU insurance plan.
Our son sporting a New York R Conference shirt.
For families there are two main plans: Value and Advantage. The primary differences between the plans are the following:
Item
Explanation
Value Plan Amount
Advantage Plan Amount
Bi-Weekly Premiums
The amount we pay every other week in order to have insurance
$160 ($4,160 annually)
$240 ($6,240 annually)
Deductible
Amount we pay directly to health providers before the insurance starts covering costs
$1,000
$800
Coinsurance
After the deductible is met, we pay this percentage of medical bills
20%
10%
Out-of-Pocket Maximum
This is the most we will have to pay to health providers in a year (premiums do not count toward this max)
$6,000
$5,000
We put them into a tibble for use later.
# use tribble() to make a quick and dirty tibble
parameters <- tibble::tribble(
~Plan, ~Premiums, ~Deductible, ~Coinsurance, ~OOP_Maximum,
'Value', 160*26, 1000, 0.2, 6000,
'Advantage', 240*26, 800, 0.1, 5000
)
Other than these cost differences, there is not any particular benefit of either plan over the other. That means whichever plan is cheaper is the best to choose.
This blog post walks through the steps of evaluating the plans to figure out which to select. Code is included so anyone can repeat, and improve on, the analysis for their given situation.
Cost
In order to figure out which plan to select we need to figure out the all-in cost, which is a function of how much we spend on healthcare in a year (we have to estimate our annual spending) and the aforementioned premiums, deductible, coinsurance and out-of-pocket maximum.
#' @title cost
#' @description Given healthcare spend and other parameters, calculate the actual cost to the user
#' @details Uses the formula above to caluclate total costs given a certain level of spending. This is the premiums plus either the out-of-pocket maximum, the actual spend level if the deductible has not been met, or the amount of the deductible plus the coinsurance for spend above the deductible but below the out-of-pocket maximum.
#' @author Jared P. Lander
#' @param spend A given amount of healthcare spending as a vector for multiple amounts
#' @param premiums The annual premiums for a given plan
#' @param deductible The deductible for a given plan
#' @param coinsurance The coinsurance percentage for spend beyond the deductible but below the out-of-pocket maximum
#' @param oop_maximum The maximum amount of money (not including premiums) that the insured will pay under a given plan
#' @return The total cost to the insured
#' @examples
#' cost(3000, 4160, 1000, .20, 6000)
#' cost(3000, 6240, 800, .10, 5000)
#'
cost <- function(spend, premiums, deductible, coinsurance, oop_maximum)
{
# spend is vectorized so we use pmin to get the min between oop_maximum and (deductible + coinsurance*(spend - deductible)) for each value of spend provided
pmin(
# we can never pay more than oop_maximum so that is one side
oop_maximum,
# if we are under oop_maximum for a given amount of spend,
# this is the cost
pmin(spend, deductible) + coinsurance*pmax(spend - deductible, 0)
) +
# we add the premiums since that factors into our cost
premiums
}
With this function we can see if one plan is always, or mostly, cheaper than the other plan and that’s the one we would choose.
R Packages
For the rest of the code we need these R packages.
We call our cost function on each amount of spend for the Value and Advantage plans.
spending <- spending %>%
# use our function to calcuate the cost for the value plan
mutate(Value=cost(
spend=Spend,
premiums=parameters$Premiums[1],
deductible=parameters$Deductible[1],
coinsurance=parameters$Coinsurance[1],
oop_maximum=parameters$OOP_Maximum[1]
)
) %>%
# use our function to calcuate the cost for the Advantage plan
mutate(Advantage=cost(
spend=Spend,
premiums=parameters$Premiums[2],
deductible=parameters$Deductible[2],
coinsurance=parameters$Coinsurance[2],
oop_maximum=parameters$OOP_Maximum[2]
)
) %>%
# compute the difference in costs for each plan
mutate(Difference=Advantage-Value) %>%
# the winner for a given amount of spend is the cheaper plan
mutate(Winner=if_else(Advantage < Value, 'Advantage', 'Value'))
The results are in the following table, showing every other row to save space. The Spend column is a theoretical amount of spending with a red bar giving a visual sense for the increasing amounts. The Value and Advantage columns are the corresponding overall costs of the plans for the given amount of Spend. The Difference column is the result of Advantage – Value where positive numbers in blue mean that the Value plan is cheaper while negative numbers in red mean that the Advantage plan is cheaper. This is further indicated in the Winner column which has the corresponding colors.
Spend
Value
Advantage
Difference
Winner
$2,000
$5,360
$7,160
1800
Value
$4,000
$5,760
$7,360
1600
Value
$6,000
$6,160
$7,560
1400
Value
$8,000
$6,560
$7,760
1200
Value
$10,000
$6,960
$7,960
1000
Value
$12,000
$7,360
$8,160
800
Value
$14,000
$7,760
$8,360
600
Value
$16,000
$8,160
$8,560
400
Value
$18,000
$8,560
$8,760
200
Value
$20,000
$8,960
$8,960
0
Value
$22,000
$9,360
$9,160
-200
Advantage
$24,000
$9,760
$9,360
-400
Advantage
$26,000
$10,160
$9,560
-600
Advantage
$28,000
$10,160
$9,760
-400
Advantage
$30,000
$10,160
$9,960
-200
Advantage
$32,000
$10,160
$10,160
0
Value
$34,000
$10,160
$10,360
200
Value
$36,000
$10,160
$10,560
400
Value
$38,000
$10,160
$10,760
600
Value
$40,000
$10,160
$10,960
800
Value
$42,000
$10,160
$11,160
1000
Value
$44,000
$10,160
$11,240
1080
Value
$46,000
$10,160
$11,240
1080
Value
$48,000
$10,160
$11,240
1080
Value
$50,000
$10,160
$11,240
1080
Value
$52,000
$10,160
$11,240
1080
Value
$54,000
$10,160
$11,240
1080
Value
$56,000
$10,160
$11,240
1080
Value
$58,000
$10,160
$11,240
1080
Value
$60,000
$10,160
$11,240
1080
Value
$62,000
$10,160
$11,240
1080
Value
$64,000
$10,160
$11,240
1080
Value
$66,000
$10,160
$11,240
1080
Value
$68,000
$10,160
$11,240
1080
Value
$70,000
$10,160
$11,240
1080
Value
Of course, plotting often makes it easier to see what is happening.
spending %>%
select(Spend, Value, Advantage) %>%
# put the plot in longer format so ggplot can set the colors
gather(key=Plan, value=Cost, -Spend) %>%
ggplot(aes(x=Spend, y=Cost, color=Plan)) +
geom_line(size=1) +
scale_x_continuous(labels=scales::dollar) +
scale_y_continuous(labels=scales::dollar) +
scale_color_brewer(type='qual', palette='Set1') +
labs(x='Healthcare Spending', y='Out-of-Pocket Costs') +
theme(
legend.position='top',
axis.title=element_text(face='bold')
)
Plot of out-of-pocket costs as a function of actual healthcare spending. Lower is better.
It looks like there is only a small window where the Advantage plan is cheaper than the Value plan. This will be more obvious if we draw a plot of the difference in cost.
spending %>%
ggplot(aes(x=Spend, y=Difference, color=Winner, group=1)) +
geom_hline(yintercept=0, linetype=2, color='grey50') +
geom_line(size=1) +
scale_x_continuous(labels=scales::dollar) +
scale_y_continuous(labels=scales::dollar) +
labs(
x='Healthcare Spending',
y='Difference in Out-of-Pocket Costs Between the Two Plans'
) +
scale_color_brewer(type='qual', palette='Set1') +
theme(
legend.position='top',
axis.title=element_text(face='bold')
)
Plot of the difference in overall cost between the Value and Advantage plans. A difference greater than zero means the Value plan is cheaper and a difference below zero means the Advantage plan is cheaper.
To calculate the exact cutoff points where one plan becomes cheaper than the other plan we have to solve for where the two curves intersect. Due to the out-of-pocket maximums the curves are non-linear so we need to consider four cases.
The spending exceeds the point of maximum out-of-pocket spend for both plans
The spending does not exceed the point of maximum out-of-pocket spend for either plan
The spending exceeds the point of maximum out-of-pocket spend for the Value plan but not the Advantage plan
The spending exceeds the point of maximum out-of-pocket spend for the Advantage plan but not the Value plan
When the spending exceeds the point of maximum out-of-pocket spend for both plans the curves are parallel so there will be no cross over point.
When the spending does not exceed the point of maximum out-of-pocket spend for either plan we set the cost calculations (not including the out-of-pocket maximum) for each plan equal to each other and solve for the amount of spend that creates the equality.
To keep the equations smaller we use variables such as \(d_v\) for the Value plan deductible, \(c_a\) for the Advantage plan coinsurance and \(oop_v\) for the out-of-pocket maximum for the Value plan.
When the spending exceeds the point of maximum out-of-pocket spend for the Value plan but not the Advantage plan, we set the out-of-pocket maximum plus premiums for the Value plan equal to the cost calculation of the Advantage plan.
When the spending exceeds the point of maximum out-of-pocket spend for the Advantage plan but not the Value plan, the solution is just the opposite of the previous equation.
#' @title calculate_crossover_points
#' @description Given healthcare parameters for two plans, calculate when one plan becomes more expensive than the other.
#' @details Calculates the potential crossover points for different scenarios and returns the ones that are true crossovers.
#' @author Jared P. Lander
#' @param premiums_1 The annual premiums for plan 1
#' @param deductible_1 The deductible plan 1
#' @param coinsurance_1 The coinsurance percentage for spend beyond the deductible for plan 1
#' @param oop_maximum_1 The maximum amount of money (not including premiums) that the insured will pay under plan 1
#' @param premiums_2 The annual premiums for plan 2
#' @param deductible_2 The deductible plan 2
#' @param coinsurance_2 The coinsurance percentage for spend beyond the deductible for plan 2
#' @param oop_maximum_2 The maximum amount of money (not including premiums) that the insured will pay under plan 2
#' @return The amount of spend at which point one plan becomes more expensive than the other
#' @examples
#' calculate_crossover_points(
#' 160, 1000, 0.2, 6000,
#' 240, 800, 0.1, 5000
#' )
#'
calculate_crossover_points <- function(
premiums_1, deductible_1, coinsurance_1, oop_maximum_1,
premiums_2, deductible_2, coinsurance_2, oop_maximum_2
)
{
# calculate the crossover before either has maxed out
neither_maxed_out <- (premiums_2 - premiums_1 +
deductible_2*(1 - coinsurance_2) -
deductible_1*(1 - coinsurance_1)) /
(coinsurance_1 - coinsurance_2)
# calculate the crossover when one plan has maxed out but the other has not
one_maxed_out <- (oop_maximum_1 +
premiums_1 - premiums_2 +
coinsurance_2*deductible_2 -
deductible_2) /
coinsurance_2
# calculate the crossover for the reverse
other_maxed_out <- (oop_maximum_2 +
premiums_2 - premiums_1 +
coinsurance_1*deductible_1 -
deductible_1) /
coinsurance_1
# these are all possible points where the curves cross
all_roots <- c(neither_maxed_out, one_maxed_out, other_maxed_out)
# now calculate the difference between the two plans to ensure that these are true crossover points
all_differences <- cost(all_roots, premiums_1, deductible_1, coinsurance_1, oop_maximum_1) -
cost(all_roots, premiums_2, deductible_2, coinsurance_2, oop_maximum_2)
# only when the difference between plans is 0 are the curves truly crossing
all_roots[all_differences == 0]
}
We then call the function with the parameters for both plans we are considering.
We see that the Advantage plan is only cheaper than the Value plan when spending between $20,000 and $32,000.
The next question is will our healthcare spending fall in that narrow band between $20,000 and $32,000 where the Advantage plan is the cheaper option?
Probability of Spending
This part gets tricky. I’d like to figure out the probability of spending between $20,000 and $32,000. Unfortunately, it is not easy to find healthcare spending data due to the opaque healthcare system. So I am going to make a number of assumptions. This will likely violate a few principles, but it is better than nothing.
Assumptions and calculations:
Healthcare spending follows a log-normal distribution
We will work with New York State data which is possibly different than New York City data
We know the mean for New York spending in 2014
We will use the accompanying annual growth rate to estimate mean spending in 2019
We have the national standard deviation for spending in 2009
In order to figure out the standard deviation for New York, we calculate how different the New York mean is from the national mean as a multiple, then multiply the national standard deviation by that number to approximate the New York standard deviation in 2009
We use the growth rate from before to estimate the New York standard deviation in 2019
We then take just New York spending for 2014 and multiply it by the corresponding growth rate.
ny_spend <- health_spend %>%
# get just New York
filter(State_Name == 'New York') %>%
# this row holds overall spending information
filter(Item == 'Personal Health Care ($)') %>%
# we only need a few columns
select(Y2014, Growth=Average_Annual_Percent_Growth) %>%
# we have to calculate the spending for 2019 by accounting for growth
# after converting it to a percentage
mutate(Y2019=Y2014*(1 + (Growth/100))^5)
ny_spend
Y2014
Growth
Y2019
9778
5
12479.48
The standard deviation is trickier. The best I can find was the standard deviation on the national level in 2009. In 2013 the Centers for Medicare & Medicaid Services wrote in Volume 3, Number 4 of Medicare & Medicaid Research Review an article titled Modeling Per Capita State Health Expenditure Variation: State-Level Characteristics Matter. Exhibit 2 shows that the standard deviation of healthcare spending was $1,241 for the entire country in 2009. We need to estimate the New York standard deviation from this and then account for growth into 2019.
Next, we figure out the difference between the New York State spending mean and the national mean as a multiple.
We see that the New York average is 1.4187464 times the national average. So we multiply the national standard deviation from 2009 by this amount to estimate the New York State standard deviation and assume the same annual growth rate as the mean. Recall, we can multiply the standard deviation by a constant.
My original assumption was that spending would follow a normal distribution, but New York’s resident agricultural economist, JD Long, suggested that the spending distribution would have a floor at zero (a person cannot spend a negative amount) and a long right tail (there will be many people with lower levels of spending and a few people with very high levels of spending), so a log-normal distribution seems more appropriate.
So we only have a 2.35% probability of our spending falling in that band where the Advantage plan is more cost effective. Meaning we have a 97.65% probability that the Value plan will cost less over the course of a year.
We can also calculate the expected cost under each plan. We do this by first calculating the probability of spending each (thousand) dollar amount (since the log-normal is a continuous distribution this is an estimated probability). We multiply each of those probabilities against their corresponding dollar amounts. Since the distribution is log-normal we need to exponentiate the resulting number. The data are on the thousands scale, so we multiply by 1000 to put it back on the dollar scale. Mathematically it looks like this.
The following code calculates the expected cost for each plan.
spending %>%
# calculate the point-wise estimated probabilities of the healthcare spending
# based on a log-normal distribution with the appropriate mean and standard deviation
mutate(
SpendProbability=dlnorm(
Spend,
meanlog=log(ny_spend$Y2019),
sdlog=log(ny_spend$SD2019)
)
) %>%
# compute the expected cost for each plan
# and the difference between them
summarize(
ValueExpectedCost=sum(Value*SpendProbability),
AdvantageExpectedCost=sum(Advantage*SpendProbability),
ExpectedDifference=sum(Difference*SpendProbability)
) %>%
# exponentiate the numbers so they are on the original scale
mutate_each(funs=exp) %>%
# the spending data is in increments of 1000
# so multiply by 1000 to get them on the dollar scale
mutate_each(funs=~ .x * 1000)
ValueExpectedCost
AdvantageExpectedCost
ExpectedDifference
5422.768
7179.485
1323.952
This shows that overall the Value plan is cheaper by about $1,324 dollars on average.
Conclusion
We see that there is a very small window of healthcare spending where the Advantage plan would be cheaper, and at most it would be about $600 cheaper than the Value plan. Further, the probability of falling in that small window of savings is just 2.35%.
So unless our spending will be between $20,000 and $32,000, which it likely will not be, it is a better idea to choose the Value plan.
Since the Value plan is so likely to be cheaper than the Advantage plan I wondered who would pick the Advantage plan. Economist Jon Hersh invokes behavioral economics to explain why people may select the Advantage plan. Some parts of the Advantage plan are lower than the Value plan, such as the deductible, coinsurance and out-of-pocket maximum. People see that under certain circumstances the Advantage plan would save them money and are enticed by that, not realizing how unlikely that would be. So they are hedging against a low probability situation. (A consideration I have not accounted for is family size. The number of members in a family can have a big impact on the overall spend and whether or not it falls into the narrow band where the Advantage plan is cheaper.)
In the end, the Value plan is very likely going to be cheaper than the Advantage plan.
Try it at Home
I created a Shiny app to allow users to plug in the numbers for their own plans. It is rudimentary, but it gives a sense for the relative costs of different plans.