Data scientists and R enthusiasts gathered for the 5th annual New York R Conference held on May 9th-11th. In front of a crowd of more than 300 attendees, 24 speakers gave presentations on topics ranging from deep learning and building packages in R to football and hockey analytics.
Speakers included: Andrew Gelman, Emily Robinson, Max Kuhn, Dan Chen, Jared Lander, Namita Nandakumar, Mike Band, Soumya Kalra, Brooke Watson, David Madigan, Jacqueline Nolis, Heather Nolis, Gabriela Hempfling, Wes McKinney, Noam Ross, Jim Savage, Ludmila Janda, Emily Dodwell, Michelle Gill, Krista Watts, Elizabeth Sweeney, Adam Chekroud, Amanda Dobbyn and Letisha Smith.
This year marked the ten-year anniversary of the New York Open Statistical Programming Meetup. It has been incredible to see the growth of meetup over the years. We now have over 10,000 members around the world!

Let’s take a look at some of the highlights from the conference:
Jonah Gabry Kicked Off “R” Week at the New York Open Statistical Programming Meetup with a Talk on Using Stan in R

Jonah Gabry from the Stan Development Team kicked off “R” week with a talk on making Bayes easier in the R ecosystem. Jonah went over the packages (rstanarm, rstantools, bayesplot and loo) which emulate other R model-fitting functions, unify function naming across Stan-based R packages, and develop plotting functions using ggplot objects.
50 Conference Attendees Participated in Pre-Conference Workshops on Thursday before the Conference

On the Thursday before the two-day conference, more than 50 conference attendees arrived at Work-Bench a day early for a full day of workshops. This was the first year of the R Conference Workshop Series. Max Kuhn, Dan Chen, Elizabeth Sweeney and Kaz Sakamoto each led a workshop which covered the following topics:
- Machine Learning with Caret (Max Kuhn)
- Git for Data Science (Dan Chen)
- Introduction to Survival Analysis (Elizabeth Sweeney)
- Geospatial Statistics and Mapping in R (Kaz Sakamoto)
The Growth of R-Ladies Summed Up in Three Pictures…



We are so excited to see the growth of the R-Ladies community and we appreciate their support for the NY R Conference over the years. Congratulations ladies!
Dr. Andrew Gelman Delivers Keynote Speech on the Fallacy of P-Values and Thinking like a Statistician—All Without Slides

There wasn’t a soul in the crowd who wasn’t hanging on every word from Columbia professor Dr. Andrew Gelman. The only speaker with a 40-minute time slot, and the only speaker to not use slides, Dr. Gelman talked about life as a statistician, warned of the perils of p-values and stressed the importance of simulation—before data collection—to improve our understanding of possible real-life scenarios. “Only through simulating fake data, can you really have statistical confidence about whatever performance metric you’re aiming for,” Gelman noted.
While we try not to pick a favorite speaker, Dr. Gelman runs away with that title every time he comes to speak at the New York R Conference.
Jacqueline and Heather Nolis Taught Us to Not to Be Afraid of Deep Learning and Model Deployment in Production

The final talk on day one was perhaps the most entertaining and insightful from the weekend. Jacqueline Nolis taught us how developing a deep learning model is easier than we thought and how humor can help us understand a complex idea in a simple form. Our top five favorite neural network-generate pet names: Dia, Spok, Jori, Lule, and Timuse!
On Saturday morning, Heather Nolis showed us how we can deploy the model into production. Heather walked through the steps involved in preparing an R model for production using containers (Docker) and container orchestration (Kubernetes) to share models throughout an organization or for the public. How can we put a model into production without your laptop running 24/7? By running the code safely on a server in the cloud!
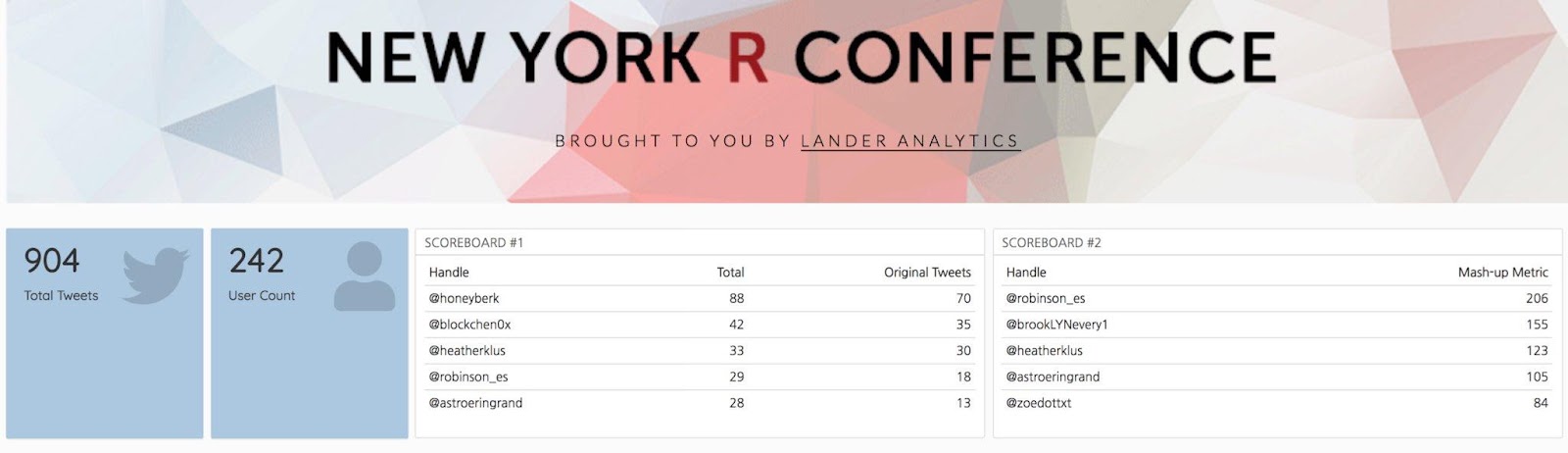
Emily Robinson and Honey Berk Win Headphones for Most Tweets During the Conference

If you’re not following Emily Robinson (@robinson_es) and Honey Berk (@honeyberk), you’re missing out! Emily and Honey led all conference attendees in Twitter mentions according to our Twitter scorekeeper Malorie Hughes (@data_all_day). Because of Emily and Honey’s presence on Twitter, those who were unable to attend the conference were able to follow along with all of our incredible speakers throughout the two-day event.
Jared Lander Debuts New-Born R Package Hex Sticker T-Shirts: Congratulations to Jared and Rebecca on the Birth of their Son, Lev

During my talk I debuted a custom R package hex sticker t-shirt with my wife Rebecca and son Lev. We R a very nerdy family.
Looking Forward to 2020
If you attended the 2019 New York R Conference, we hope you had an incredible experience. If you did not attend the conference, we hope to see you next year!
Jared Lander is the Chief Data Scientist of Lander Analytics a New York data science and AI firm, Adjunct Professor at Columbia University, Organizer of the New York Open Statistical Programming meetup and the New York and Government Data Science and AI Conferences and author of R for Everyone.














































{kind=link}